reactive functional pipelines
Intro
this note is about an itch I had for some time now… about how to use the reactive spring stack and how to make a java app as functional as the language and tools support.
we are going to create a modular app that will take advantage of webflux, webclient, and hazelcast.
with those components we will try to build a low latency + reactive + non-blocking + strategy backed, multipurpose engine that should be flexible enough to adapt through the evolution of an app.
this could solve the one too many times of our codebase going wild when an application starts small, and we add many new features or client requirements to it.
the most common example of the above is the video club store one. We start with an app that handles requests and looks for data on one end plus adds data on another. A client wants to rent a video on one end, and we add movies and actors and directors to our backing database on the other. The video club can be a suppliers service, an employees roster, a goods stock system… we’ve all been there.
this all started when trying to build a lightweight cloud service, backpressure and responsive ready a while ago, let’s check the first part of the solution! (the second part, Quarkus + graal + native images is coming soon)
What I understand as Functional
from wikipedia functional programming entry
In computer science, functional programming is a programming paradigm where programs are constructed by applying and composing functions. It is a declarative programming paradigm in which function definitions are trees of expressions that map values to other values, rather than a sequence of imperative statements which update the running state of the program.
thou the above is ok, I understand functional programming like this: it is programing by delegation
delegation of the imperative code that does the actual computation. When we see .filter, behind the scenes, there is an if somewhere evaluating to true or false, or maybe a cmp followed by a je, jne, jz or jnz.
the actual Optional -> .filter implementation looks like this
public Optional<T> filter( Predicate<? super T> predicate )
{
Objects.requireNonNull( predicate );
if ( !isPresent() )
{
return this;
} else
{
return predicate.test( value ) ? this : empty();
}
}
that looks NOT functional at all… but… it powers functional programming in java.
when we use the filtering within an Optional we delegate the implementation to the Optional code. We care more about the functionality than the implementation. The way it is built, and the possibility of chaining multiple filtering calls, enhances readability by a lot and puts our intention in front of our implementation.
Note: this does not mean you can get away with a bad implementation for the sake of a programming style…
maybe my extra twist in understanding is incorrect, but it allowed me to think the following.
How about a functional app where the different steps we have to do, are delegated to internal implementations. Instead of if then else, how about we make our application behave like the java Optional where we can pipeline different actions that are very clear to read, and we delegate the implementation to them.
Setting the scene
From Java framework to Project reactor.
Optional, Streams, Function, etc, they are all bundled in the core of Java. They are very powerful per se, but then… reactor!
project reactor introduces reactive streams to build non-blocking, low latency java apps.
the reactor tech is at the core of the app we are going to build so let’s make a tiny sample of how we can use it.
a small reactive pipeline similar to what we know with java.
Mono.just( "this is a string" )
.map( String::toUpperCase )
.doOnNext( System.out::println )
.subscribe();
the above is very similar to what we know already on the java libs with a few things worth explaining
- Mono: it is a reactive-streams publisher that at the end of it’s processing returns (emits) a single item
- map: same thing as in java, transforms the input by applying a function
- doOnNext: this is what will happen when the pipeline returns successfully
- subscribe: think of this as a “wait for it…” command, without subscribing nothing happens
so on the toy example above, we create a reactive stream out of a string, we convert it to upper case, next we print the result to console, and we subscribe to it.
Reactive streams and functional programming meet strategy pattern
we talked about delegation of implementation and what better to delegate than the strategy pattern…
again from the wikipedia strategy pattern entry:
In computer programming, the strategy pattern (also known as the policy pattern) is a behavioral software design pattern that enables selecting an algorithm at runtime. Instead of implementing a single algorithm directly, code receives run-time instructions as to which in a family of algorithms to use.[1]
Strategy lets the algorithm vary independently from clients that use it.
so… if we add all the above together our academic project has for the moment:
- java
- reactive streams
- functional style
- behavioral pattern (strategy)
before moving into the last ingredient let’s make a small example of this 4 elements above
return Mono.just( DemoDomainObject )
.flatMap( dbService::get )
.flatMap( brokerService::putAsync )
.flatMap( resultService::returnSlice );
so, on the above, we start a reactive stream with a demo object, we then pass it to the dbService, and then to the broker service, and then to the result service….
each step transformed the object and passed the baton on to the next.
let’s make an easy-to-understand strategy context to finish this section.
so, you have to get what is required from the db? then which repo to use…? you could call the proper repo on the individual input handler, or you can also not care at all and call the same method for any input and let your strategy decide… Let’s implement the latter!
if the demo object had for example a type field… we can match that type to a repository…
lets try this with a map
Map<String, DbStrategy> mapOfStrategies = Map.ofEntries(
new AbstractMap.SimpleImmutableEntry<>( "supplier", new SupplierDbStrategy() ),
new AbstractMap.SimpleImmutableEntry<>( "transport", new TransportDbStrategy() ));
DbStrategy dbStrategy = mapOfStrategies.get( demoDomainObject.getType() );
dbStrategy.findOne()
we have there 2 strategies that will be put into a map. In runtime when we get a demo object, the proper one will be selected based on the type, and then we execute the findOne() method of that strategy.
the above is very naive but illustrates the following:
we created a reactive-stream pipeline of actions… which delegates operations to services… which themselves delegate the actual implementation to final strategies…
as stated in the intro: programing by delegation.
last piece of the puzzle: In Memory Data Grid
say we perform all that with real services, we will want to put a cache in front of the first step, so in case we have already responded to a request, we just skip the heavy lifting of going to our back-end and we reply immediately with in memory data.
I chose hazelcast as the cache for a myriad of reasons, but one very attractive is that it can handle our local and server caches and also it can work embedded on spring boot apps, so it is an ideal fit for academic apps, and of course production apps.
into implementation
repos and runner
- you are required to have
java 16but anything fromjava 11and above should be ok - all the code for this project can be found here in github
- to run it just clone it, and hit run on your ide preferably on debug mode, so you can breakpoint the code, and examine what is happening
- configure your ide to run with
localas active profile
- configure your ide to run with
- or you can also manually run it like this:
mvn spring-boot:run -Dspring-boot.run.profiles=local - everything is properly commented / documented on the repo, examples here might not have all javadocs nor comments for brevity
- you can, if you want, run many instances of the app by only changing the server ports, and you will be able to see a hazelcast cluster form on your local machine, with each instance of the app connecting to the other instances of the cache cluster!!
- instance 1: mvn spring-boot:run -Dspring-boot.run.jvmArguments=”-Dserver.port=8081 -Dmanagement.server.port=18081”
- instance 2: mvn spring-boot:run -Dspring-boot.run.jvmArguments=”-Dserver.port=8082 -Dmanagement.server.port=18082”
- instance x: […]”-Dserver.port=xxxx -Dmanagement.server.port=xxxxx”
the local profile is configured to output all debug logs, so you can follow step by step what is going on
as the rest of the code in this site, use it at your own will with no guarantee whatsoever.
you can, if you want and you run on java 9 or above, add the following jvm options so hazelcast runs without complaints:
--add-modules java.se
--add-exports java.base/jdk.internal.ref=ALL-UNNAMED
--add-opens java.base/java.lang=ALL-UNNAMED
--add-opens java.base/java.nio=ALL-UNNAMED
--add-opens java.base/sun.nio.ch=ALL-UNNAMED
--add-opens java.management/sun.management=ALL-UNNAMED
--add-opens jdk.management/com.sun.management.internal=ALL-UNNAMED
nothing will break if you don’t
once u have one or more instances of the app running, simply hit
- to get all posts: localhost:8081/posts
- to get a single post: localhost:8081/posts/1
- to get all comments for a post: localhost:8081/posts/1/comments
BONUS: running hazelcast management center
if you want to see how the cache entries come and go, you can run the docker image for the hazelcast management center like this:
sudo docker run --rm -p 9080:8080 hazelcast/management-center:latest
then point your browser at localhost:9080 to access the management center and configure it with the cluster name: bare-metal-cluster and with your ip:port for hazelcast that will show up when you run the app, if you have more than one instance configure them all.
at first the management center will be almost empty but, as you hit the app endpoints you will see how the maps get created, and how the entries will appear and get evicted as their TTL hits.
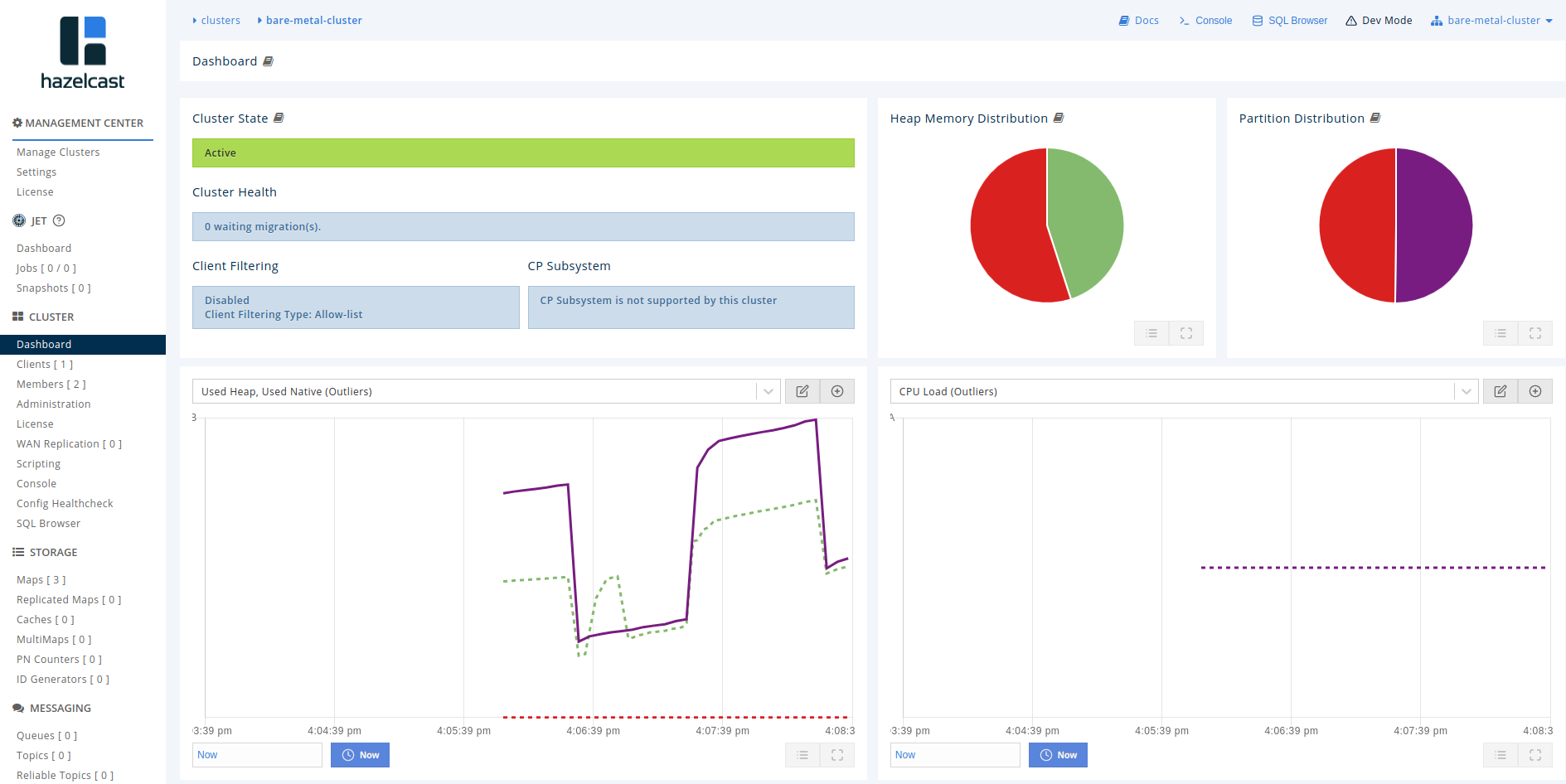
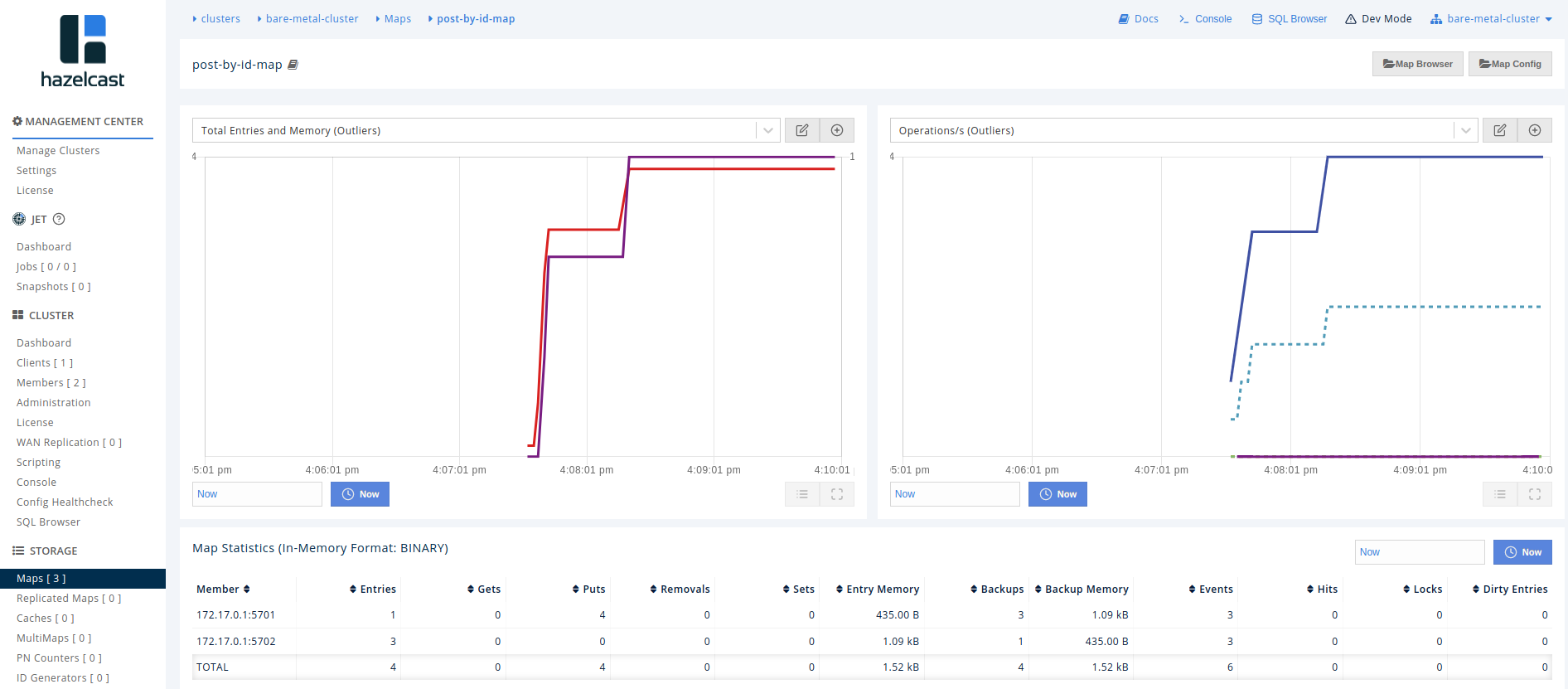
this is how the management center will look like with 2 instances, and the 3 maps already created:
dashboard:
map metrics:
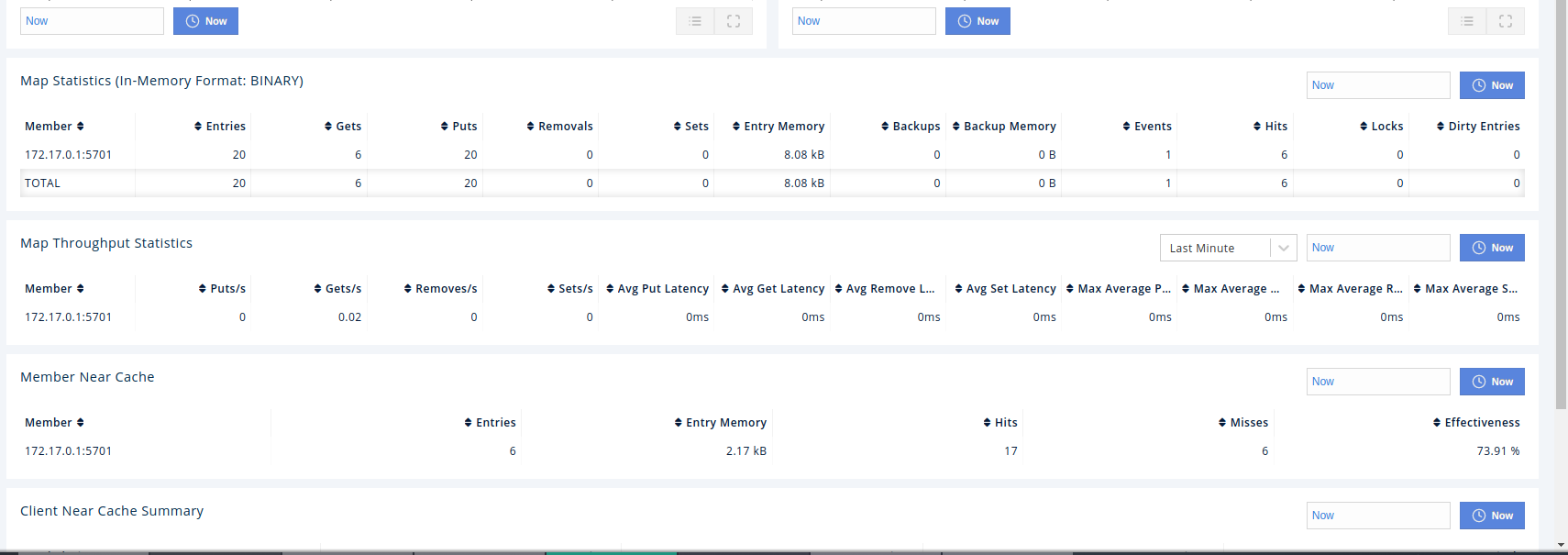
map metrics with near caches on a single member cluster:
the MAIN idea to explore functional reactive programming
so to explore everything laid out in the introductory part, this is what we are going to build.
we will build a proper engine that will:
- accept requests from different rest endpoints
- validates the input
- responds from cache
- if cache misses, gets data from a real web service:
- transforms the response from our fake REST vendor
- stores it in cache for future use
- responds to the original caller.
all that in a functional reactive non-blocking strategic manner
the entry point of the system
this system takes its input from a netty reactive webservice. We have 2 controllers one for comments and another one for posts that are completely standard.
the only thing to check out is how little code there is on the routes, just some building of headers and passing them with the serverResponse to the main engine.
let’s see the code for the comment’s one as it is the smallest.
@RestController
@RequestMapping( produces = "application/json" )
@RequiredArgsConstructor
@Log4j2
public class CommentsController
{
private final PipelineEngine engine;
private final AppConfig config;
@GetMapping( path = "/posts/{postId}/comments" )
public Mono<String> getAllCommentsForPostById( final ServerHttpResponse serverHttpResponse, @PathVariable( "postId" ) final String postId )
{
log.debug( "received request for all comments for postId: {}", postId );
final HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.set( config.getHeaders().getStrategyHeader(), config.getStrategies().getCommentsByPostId() );
httpHeaders.set( config.getHeaders().getPostIdHeader(), postId );
return engine.processMessage( httpHeaders, serverHttpResponse );
}
}
very standard and very simple, no logic is applied here, just building headers and passing the baton to the engine.
the core of the Engine
the core will be no more than a Mono pipeline of mappings going through all the services we want to execute.
let’s take a look
@Component
@Log4j2
@RequiredArgsConstructor
public class PipelineEngine
{
private final ValidationService validationService;
private final ExternalDataService externalDataService;
private final DataProcessingService dataProcessingService;
private final HttpService httpService;
private final CacheService cacheService;
private final CacheKeyService cacheKeyService;
public Mono<String> processMessage( HttpHeaders rwHttpHeaders, ServerHttpResponse serverHttpResponse )
{
log.debug( "message entering -http- processing pipeline" );
final PipelineMessage message = new PipelineMessage().setHeaders( rwHttpHeaders );
message.setServerHttpResponse( serverHttpResponse );
return processMessage( message )
.flatMap( httpService::buildResponse );
}
public Mono<PipelineMessage> processMessage( PipelineMessage message )
{
log.debug( "message entering -main- processing pipeline" );
return Mono.just( message )
.filter( message1 -> true )
/*1*/.flatMap( validationService::validate )
/*2*/.flatMap( cacheKeyService::generateKey )
/*3*/.flatMap( cacheService::get )
/*4*/.flatMap( externalDataService::get )
/*5*/.flatMap( dataProcessingService::processData )
/*6*/.flatMap( cacheService::put )
/*7*/.onErrorResume( error ->
{
log.error( "error on pipeline: {}", error.getMessage() );
Optional.ofNullable( message.getHttpStatus() )
.ifPresentOrElse(
ignoreIfNotNull -> Function.identity(),
() -> message.setHttpStatus( HttpStatus.INTERNAL_SERVER_ERROR ) );
return Mono.just( message );
} );
}
}
ok, that’s it!, this is the entire core of the application.
there are 2 methods to observe.
- processMessage with httpHeaders and a serverResponse
- the same method overloaded to accept a message
let’s examine what will happen when we get a request to get all the post from the webservice.
- webservice pipeline steps:
- 1: we build a message from the request using the headers (basically a very handy multimap) and the serverResponse
- 2: we pass the message to the main pipeline
- 3: we get the message processed by the pipeline and perform a final transformation to return it to the caller of the service.
- main pipeline steps:
- 1: we validate the input from the web service
- 2: we generate a cache key for the given request
- 3: we try to find the requested data internally in our cache and, if found, we mark the record to skip the rest of the pipeline
- 4: we call the external data service if data was not found internally
- 5: we process the external response as required, this could be json or xml transformations, trimmings, splittings, etc
- 6: we put the processed data into the cache asynchronously (fire & forget)
- 7: in case one of the steps throws an error, we gracefully handle it and move on, we do not crash the pipeline
- result: we return the message properly processed with payload and httpStatus, and in case the data was new or refreshed, we put it in the cache
each one of te steps can be skipped if the message is properly marked, and as you can see, we don’t actually know how things are being done… but we do know WHAT is being done…
it is very easy to figure out what our engine is about, and if for example tomorrow you don’t want to have cache anymore… you can comment the cache line, that’s it, all the code behind it is gone, almost like a built in naive feature flag.
Of course, with minimum effort each service could be configured via externalized configuration, to always be skipped transforming it into a powerful on-engine feature flag!
now, let’s see how a common service work.
the core of the services.
to explore the services structure, we are taking the cache service as illustrative example
the cache service example
each service has 5 parts
- the service itself, which acts as a context gateway for the strategy pattern, that has the methods to be called by the pipeline.
- the top cache strategy that has the contract the rest of the strategies will implement
- a generic context / target strategy, in the strategy pattern sense, which will be the one that will choose which strategy will execute
- a base strategy that has a self-identifying method to be implemented by each strategy and global configuration object to be shared by all
- the series of strategies that will have the actual implementation code.
the cache service itself
let’s check the service code:
it contains the methods you see called from the pipeline engine.
the cache service, as all other services, extend the targetStrategy with the targeted strategy type.
it is then in charge of exposing methods to the pipeline to call, in this case put() and get() and determines what will be processed, and what will be the fallback for the service. This service gives a great deal of flexibility to skip steps if desired, or allows to implement an in-house feature-flag configurable by external markers.
@Service
@Log4j2
@RequiredArgsConstructor
public class CacheService extends TargetStrategy<CacheServiceStrategy>
{
public Mono<PipelineMessage> put( final PipelineMessage message )
{
final String strategyId = message.getHeaders().getFirst( getConfig().getHeaders().getStrategyHeader() );
final BiFunction<CacheServiceStrategy, PipelineMessage, Mono<PipelineMessage>> action = CacheServiceStrategy::put;
return applyStrategy( message, message, strategyId, action, Mono::just );
}
public Mono<PipelineMessage> get( final PipelineMessage message )
{
final String strategyId = message.getHeaders().getFirst( getConfig().getHeaders().getStrategyHeader() );
final BiFunction<CacheServiceStrategy, PipelineMessage, Mono<PipelineMessage>> action = CacheServiceStrategy::get;
return applyStrategy( message, message, strategyId, action, Mono::just );
}
}
the top cache strategy itself
let’s check the cache strategy code:
it contains the contract all our deriving cache strategies will implement
@Service
public abstract class CacheServiceStrategy extends BaseStrategy
{
public abstract Mono<PipelineMessage> put( PipelineMessage message );
public abstract Mono<PipelineMessage> get( PipelineMessage message );
public abstract String getMapName();
public abstract Long getTTL();
as you can see we have a contract here…
- put: how do we put things in the cache
- get: how do we get things from the cache
- getMapName: the cache’s map name to store things into
- getTTL(): the time to live of a given data type. We can individually configure a record’s TTL per map!
the target strategy (generic context)
let’s check the context code:
@Log4j2
public abstract class TargetStrategy<T extends BaseStrategy>
{
@Autowired
private List<T> strategiesList;
@Getter( PROTECTED )
private Map<String, T> strategiesMap;
@Autowired
@Getter( PROTECTED )
private AppConfig config;
@PostConstruct
private void populateStrategiesMap()
{
strategiesMap = strategiesList.stream()
.collect( toMap( BaseStrategy::getStrategyId, Function.identity() ) );
}
protected <U, R> Mono<R> applyStrategy( final PipelineMessage message, final U inputToProcess, final String strategyId, final BiFunction<T, U, Mono<R>> action,
final Function<U, Mono<R>> fallbackAction )
{
return Mono.just( skipStep( message ) )
.filter( shouldWeSkipStep -> !shouldWeSkipStep )
.flatMap( ignoreBooleanIfWeDontSkipStep ->
Optional.ofNullable( strategiesMap.get( strategyId ) )
.map( strategy ->
{
log.debug( "strategy executed: {}", strategy.getClass().getSimpleName() );
return action.apply( strategy, inputToProcess );
} )
.orElseGet( () ->
{
log.error( "no {} strategy registered for strategyId: {}", this.getClass().getSimpleName(), strategyId );
return fallbackAction.apply( inputToProcess );
} ) )
.switchIfEmpty( fallbackAction.apply( inputToProcess ) );
}
protected Boolean skipStep( PipelineMessage message )
{
String skipAll = message.getHeaders().getFirst( getConfig().getHeaders().getSkipAllHeader() );
return Boolean.parseBoolean( skipAll );
}
}
as you can see there are a few java + spring tricks.
- first trick: autowiring all related strategies.
- a service extending this class will tell it which Strategy type it is extending… because of that, when the service bean comes into play, its own list of strategies is autowired with the correct types. Spring auto-magic!
- second trick: use of
@PostConstruct.- this allows for our map to be properly populated and ready to use.
this class is the actual strategy selector and executor for each service. We call the applyStrategy() method from any service with a strategyId among its arguments. If we find the strategyId we execute the implementation code, or else we have a fallback action if the strategyId is not recognized.
this class also allows for each service to override the skipStep() method so if you don’t want to execute something you just tell it how to skip! By default, it skips execution if it finds the skipAllHeader to be set and to be true.
the base strategy
let’s check the base strategy code:
all strategies derive from this base strategy, which only purpose is to give a way for each strategy to identify itself, and passes down the main application configuration
@Getter( PROTECTED )
public abstract class BaseStrategy
{
@Autowired
private AppConfig config;
/**
* Gets the strategy name.
*
* @return the string identifying a given strategy
*/
public abstract String getStrategyId();
the IMDG strategy
let’s check the IMDG strategy code:
this one actually has the hazelcast code to put and get records from the cache. This strategy will be extended by anyone who wants to use hazelcast as a cache.
say tomorrow it’s redis, or apache geode… no problem, just implement the geode strategy.
so you want to mix redis and memcached and hazelcast? still no problem… implement redis and memcached and have the strategies to extend the one u want and u can use them all together, and they will get auto selected according to the data-type or other criteria you can think of.
it will just work… That simple!
as you can see on the code below, this one is a bit more complex. We have a few safeguards for null keys or disconnected clusters, but bar that it is an async put to the cache and a sync get from the cache.
the fact that putting a record into the cache is async, allows for a fire and forget functionality. If someone requested data we don’t want them waiting because our cache is lagging or there are connectivity problems.
@Service
@Log4j2
public abstract class IMDGCacheServiceStrategy extends CacheServiceStrategy
{
@Qualifier( "hazelcastInstance" )
@Autowired
private HazelcastInstance cache;
@Override
public Mono<PipelineMessage> put( final PipelineMessage message )
{
String cacheKey = message.getHeaders().getFirst( getConfig().getHeaders().getCacheKeyHeader() );
String cacheValue = message.getDataPayload();
Optional.ofNullable( cacheKey )
.ifPresentOrElse( key ->
{
try
{
cache.getMap( getMapName() ).putAsync( cacheKey, message.getDataPayload(), getTTL(), TimeUnit.SECONDS );
log.debug( "putting record to cache - key: {}, value: {}", key, cacheValue.replace( "\n", "" ) );
}
catch ( IllegalStateException | IllegalArgumentException exception )
{
log.error( "error putting record to cache - error: {}", exception.getMessage() );
}
},
() -> log.debug( "null cache key: nothing to put to cache" ) );
return Mono.just( message );
}
@Override
public Mono<PipelineMessage> get( final PipelineMessage message )
{
String cacheKey = message.getHeaders().getFirst( getConfig().getHeaders().getCacheKeyHeader() );
Optional.ofNullable( cacheKey )
.ifPresentOrElse( key ->
{
try
{
Optional.ofNullable( cache.getMap( getMapName() ).getEntryView( key ) )
.ifPresentOrElse( entryView ->
{
String recordValue = String.valueOf( entryView.getValue() );
message.setDataPayload( recordValue );
message.getHeaders().set( getConfig().getHeaders().getSkipAllHeader(), "true" );
LocalDateTime expirationTime = ofInstant( ofEpochMilli( entryView.getExpirationTime() ), ZoneId.of( "Z" ) );
log.debug( "cache hit for key: {}, expiration time: {}, value: {} ", key, expirationTime.format( ISO_LOCAL_DATE_TIME ),
recordValue.replace( "\n", "" ) );
},
() -> log.debug( "cache miss for key: {}", key ) );
}
catch ( IllegalStateException | IllegalArgumentException exception )
{
log.error( "error getting record from cache - error: {}", exception.getMessage() );
}
},
() -> log.debug( "null cache key: nothing to get from cache" ) );
return Mono.just( message );
}
}
the All Posts strategy
let’s check the all posts strategy code:
this strategy is the one chosen (strategy design pattern…) when there is a request for all posts. It identifies itself with its own strategyId, tells the cache what its map name is, what the ttl for its entries is, and extends hazelcastStrategy… and that’s it.
If you want to swap the cache in the future, then just have this strategy extend the cache of your choosing, and you are good to go.
@Service
public class PostsAllDataGridServiceStrategy extends IMDGCacheServiceStrategy
{
@Override
public String getStrategyId()
{
return getConfig().getStrategies().getPostsAll();
}
@Override
public String getMapName()
{
return getConfig().getCache().getPostsAll();
}
@Override
public Long getTTL()
{
return Long.valueOf( getConfig().getCache().getPostsAllTtl() );
}
}
the webclient
this is a reactive webclient that we use to call our rest APIs on the web
let me describe the reactive webclient pipeline that is happening here
- reactive webclient pipeline:
- 1: we set the method to use on the call
- 2: we set the path to use on the call
- 3: we set headers to only accept json as response
- 4: we set a body if there is one
- 5: we call the retrieve method
- 6: we convert the response into an entity of the String type
- 7: we flatMap the response to extract the body and status into the pipeline message
- 8: in case of error we set the proper error code
- result: we return the message with proper payload and httpStatus
@Service
@Log4j2
public class VendorWebclient
{
private final WebClient webClient;
public VendorWebclient( AppConfig appConfig )
{
webClient = WebClient.builder()
.baseUrl( appConfig.getVendor().getBaseUrl() )
.build();
}
public Mono<PipelineMessage> requestData( PipelineMessage message )
{
final HttpMethod apiCallMethod = message.getApiCallMethod();
final String apiCallPath = message.getApiCallPath();
final String apiCallBody = message.getApiCallBody();
log.debug( "calling vendor api with httpMethod: {}, at path: {}, with body: {}", apiCallMethod, apiCallPath, apiCallBody );
final WebClient.RequestBodySpec clientWithMethodAndPath = webClient
.method( apiCallMethod )
.uri( apiCallPath )
.accept( APPLICATION_JSON );
Optional.ofNullable( apiCallBody ).ifPresent( clientWithMethodAndPath::bodyValue );
return clientWithMethodAndPath
.retrieve()
.toEntity( String.class )
.flatMap( responseEntity ->
{
final String body = responseEntity.getBody();
final HttpStatus httpStatus = responseEntity.getStatusCode();
log.debug( "received from vendor - status-code: {}", httpStatus.value() );
log.debug( "received from vendor - body: {}", body.replace( "\n", "" ) );
message.setHttpStatus( httpStatus );
message.setDataPayload( body );
return Mono.just( message );
} )
.onErrorResume( WebClientResponseException.class, responseException ->
{
final String errorMessage = responseException.getMessage();
final HttpStatus httpStatus = responseException.getStatusCode();
log.error( "ERROR from vendor - error-code: {}", httpStatus.value() );
log.error( "ERROR from vendor - errorMessage: {}", errorMessage );
message.setHttpStatus( httpStatus );
message.setDataPayload( errorMessage );
return Mono.just( message );
} );
}
}
extra goodies not covered on this post
you will notice there are a few things not covered such as:
- objectified configuration files
- yaml configuration files, particularly the main application.yaml one
there is not much to comment on those files, except maybe take a look at the configuration ones, as most variables if not all of them, have been externalized. That approach provides the app with incredible flexibility.
final thoughts and conclusion
fun fact: there is not a single if or else or switch or while or for in the around 2K lines of code. None that we can see that is… remember that we delegated the implementation to spring and reactor…
when this application runs, it will do so on a functional, reactive, non-blocking stack.
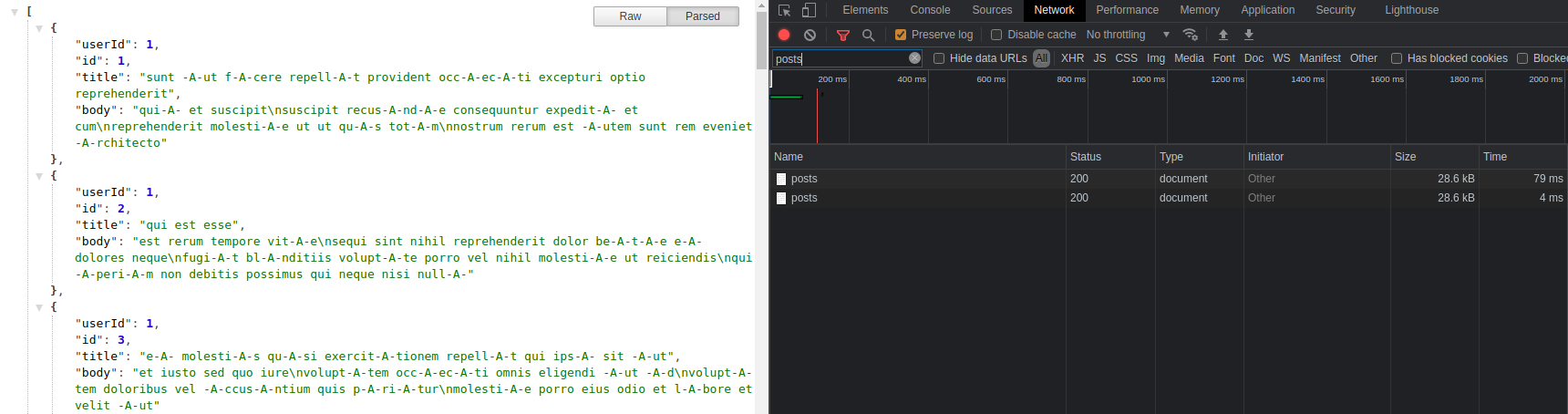
when ran on my computer, the first call to all posts can take around 70 to 300ms, while the second one takes between 2ms and 8ms
this first call runs all the pipeline as nothing is yet cached. The engine has to go to the web to get the data from the rest service, come back, put the payload on the cache, and finally respond. There is a high network tax that we pay on the first run getting data from the external rest APIs
the second call, will hit the cache and mark the message to skip the rest of the pipeline! pure performance!
Functional programming is not a master key to unlock every problem and probably computation that requires the actual implementation cannot make use of it, or might be a poor use of the paradigm.
In this particular case, the readability and extensibility of the project were greatly improved by using functional techniques and applying the strategy pattern.
A warning on patterns: if not used properly, they can cause more problems that what they solve.
Impossible to describe that scenario better than the immense Venkat S in another of his mind bending videos.
I hope that you run this project yourself, and improve it with your own ideas. A few worth considering to play with:
- have a strategy run a series of other strategies. Very useful for validations as many inputs might have a common validation. How could we run all of them, or a few of them depending on the data type?
- how easy would it be to transform this pipeline in say, 3 or 4 microservices.
- what more could we do with hazelcast? near-caches? pre-population of near-caches?
- how to implement in-engine feature flags controlled by configuration?
- can you add another entry point? say a broker? an event of some sort?
hope you enjoyed!
Johnny