AWS – REST system with Java native
Intro
Purpose
having used nodejs and python on aws lambdas but being a JVM developer for business apps, I was curious about native java stack performance on AWS Lambda.
This note is about building a REST service using java and some promising frameworks around it, to see how competitive Java can be on the AWS serverless stack
About Serverless by AWS
Serverless services offered by AWS are a family of resources for which we don’t need to take care of provisioning nor configuration of the underlying infrastructure. You still configure the targeted resource, such as networking or max running time, but you don’t need to worry about instances, or pods, or cores, or scaling, etc…
so yes… there are servers behind the scenes, and no… you don’t need to care about them.
the interesting side of these resources is that they are usually very cost-effective, and are commonly billed on a “pay as you use” scheme. Using AWS Lambda as an example, you pay per requests, resources, and running time, so if your usage is minimum, your expenses will also be.
if you combine low costs of paying as you use, and hassle-free provisioned infrastructure, a few of these services become VERY attractive for many use cases.
Possible Use cases
so, what requires little processing, not much ram, short response times or not response at all?
well… how about these cases:
- REST services
- cron jobs
- email / sms sending
- app configurations storing and processing
- user preferences storing and processing
- website analytics preprocessing (“clicks”)
- various middlewares
- etc…
when u land one of the requirements above, and adding dev, test, uat, prod environments for your service… affordable serverless arch hits the target.
remember that, this tool as any other, won’t fit every need.
Assumptions
this is not a from scratch tutorial
the focus here is the java code and libraries to build an AWS lambda service and testing its performance.
I assume you know Java, AWS services and how to create / modify resources such as dynamo, roles etc.
What are we building?
The -simple- REST Service System
we are going to build a simple REST service that is ubiquitous on business apps. It will return data stored on a dynamoDB via different endpoints.
the service will return JSON responses much like jsonplaceholder.
Why this service?
this service is driven by a very simple and small architecture that is powerful enough to serve a REST mock service like the site mentioned before.
it can be used by shops during dev phases when a vendor gives us a json schema but has not yet deployed their own services. With this we can still code and hit our mock service and never be blocked by vendors.
Why with Java?
- the intention of this note is to put a new tech around Java to the test on the serverless stack.
- right now java is usually a no-no on lambdas, so we resort to node, python, etc…
- the shops I worked (and work) for, use java extensively.
- being able to the boost their most prevalent back-end tech and personnel is a major win.
if we could manage to build fast-starting, lightweight services using java, we could finally turn the page on “java is slow and heavy for lambdas”, and harness the power of the existing devs in jvm shops.
Ready… set… GO!
this simple REST service will look like the diagram below

- there will be a user request for a given json datum.
- AWS API Gateway will be responsible for forwarding that request to the lambda where our business code is.
- the lambda will return the requested data by returning cached data from memory, or querying AWS Dynamo DB if cache misses.
GitHub Repo
clink on this link for the code for this note on GitHub
Reference documentation
we used
- AWS API Gateway
- as our REST Api entry point
- AWS Lambda
- as our computing resource
- AWS DynamoDB
- as our non SQL storage solution
- as topics for a serverless broker
- Java as implementation language
- Quarkus
- a java framework that promises fast performance with little footprint and many other fun features.
- AWS lambda guide: quarkus.io guides amazon-lambda
- AWS Dynamo DB guide: quarkiverse.github.io quarkiverse-docs amazon-dynamodb
- Cache guide: quarkus.io guides cache
- GraalVM an implementation of the JDK that promises high performance for JVM apps (and others…) and more interestingly, native Java apps
NOTE: it is fair to mention that the team at Spring is also working on supporting native compilation!
Implementation components
Quarkus will create a minimal AWS SAM template that will help create and deploy the following components:
- Cloudformation template
- AWS API Gateway
- AWS Lambda using our packaged java code
- IAM role
I created / updated manually
- dynamoDB tables
- updated IAM role to fit my own requirements
you can, if you want, configure every resource by modifying the template generated by Quarkus, or take a step further and use Serverless if that’s your weapon of choice
so basically the only thing we need to examine here is the Java service:
REST Service
the pom.xml
nothing worth noting here except for the native build profile that will allow us to generate a native running app from our java code
the POJOs
I made 3 simple classes to contain our data
in the User class I added a UserAddress field to give this test project a little more reality feel…
the resources (controllers)
I made 2 controllers that will handle requests for users and for articles
the articles controller has 4 methods
- GET:
- get all articles
- get a given article by id
- get all articles for a given user by user id
- POST:
- save/update an article to the database
the users controller has also 4 methods
- GET:
- get all users
- get a given user by id
- get all users belonging to a given country
- POST:
- save/update a user to the database
I will save what a Uni means for when we check the database services
the repositories (database)
this is a little more interesting as it interacts with the dynamoDB tables using dynamoDB async and Quarkus async mutiny libraries.
these repositories, given the small size of the project, are a mix of proper database ops and service ops. To keep the code simple I created just one service/repo class for users and another one for articles operations.
let’s use the articlesRepo for a few comments (which apply to the usersRepo too)
Uni
- this is mutiny’s way of handling async operations
- it behaves in a similar way as other libs of the sort, having completion stages, actions on failure or response and post ops.
extending from DynamoOps
Scanning and getting items requests are common operations that I wrapped into the DynamoOps class to reuse them everywhere, modifying a little Quarkus guides’ approach
saving to DynamoDB
let’s check the putArticle method
protected PutItemRequest putArticle(final Article article) {
return PutItemRequest.builder()
.tableName(TABLE_NAME)
.item(DomainMapper.fromArticle(article))
.build();
}
this is fairly straightforward, we build a PutItemRequest that specifies what to save to which table.
the DomainMapper will help us build AWS DynamoDB object to be stored.
let’s now check the putAsync Method
public Uni<List<Article>> putAsync(final Article article) {
return Uni.createFrom()
.completionStage(() -> dynamoDbAsync.putItem(putArticle(article)))
.onItem()
.ignore()
.andSwitchTo(this::findAll);
}
this is the method that will be called by the controller to perform the save operation.
after calling the dynamo client to store the data, it ignores the result if successful and calls the findAll method. By doing this we return to the end user the list of articles we now have on the DB after storing one.
reading from DynamoDB
we have 3 read operations to comment
doing a full db read
@CacheResult(cacheName = "articles-all")
public Uni<List<Article>> findAll() {
return Uni.createFrom()
.completionStage(() -> dynamoDbAsync.scan(scanRequest(TABLE_NAME)))
.onItem()
.transform(scanResponse -> scanResponse.items()
.stream()
.map(DomainMapper::toArticle)
.collect(Collectors.toList()));
}
this is the equivalent of a select * from a given table, we get all records from dynamo. We use the scanRequest helper method to build the required ScanRequest.
2 things are worth noting:
- the
@CacheResultannotation.- this is an in memory cache
- it will die when the lambda is deprovisioned
- keep reading to find out why I put a cache on a “volatile” deployment
- the
.transformoperation on theUnichain- given that we get back a dynamoRecord, and we want the data returned to be our own POJO, we map dynamo records to our own domain objects
doing a selection by the table’s partition key
@CacheResult(cacheName = "articles-by-id")
public Uni<Article> findById(final String articleUuid) {
return Uni.createFrom()
.completionStage(() -> dynamoDbAsync.getItem(findById(articleUuid, COL_UUID, TABLE_NAME)))
.onItem()
.transform(response -> DomainMapper.toArticle(response.item()));
}
AWS sdk provides a getItem method for DynamoDB when you are targeting a selection by the tables primary Key, avoiding you the trouble of creating a query for that. We also use the findById helper method to build the required GetItemRequest.
doing a selection over a specific document’s attribute
@CacheResult(cacheName = "articles-by-user-id")
public Uni<List<Article>> findArticleByUserId(final String userUuid) {
return Uni.createFrom()
.completionStage(() -> dynamoDbAsync.scan(scanSingleAttribute(userUuid, ":userUuid",
"userId = :userUuid", TABLE_NAME)))
.onItem()
.transform(scanResponse -> scanResponse.items()
.stream()
.map(DomainMapper::toArticle)
.collect(Collectors.toList()));
}
here we use the .scan method and a helper method to return the required ScanRequest. just like before we map the response to our own data type.
helper methods
these methods return the data types required by dynamo SDK to perform the read requests. They are on their own separate class as we reused them for articles and users
full scan request:
protected ScanRequest scanRequest(final String tableName) {
return ScanRequest.builder()
.tableName(tableName)
.build();
}
this method builds a scan request that will return all data from a given table
you just need the table’s name.
single item request:
protected GetItemRequest findById(final String uuid, final String uuidColumn, final String tableName) {
Map<String, AttributeValue> getItemKey = new HashMap<>();
getItemKey.put(uuidColumn, AttributeValue.builder().s(uuid).build());
return GetItemRequest.builder()
.tableName(tableName)
.key(getItemKey)
.build();
}
this method builds a request that will return a single item looking for the table’s primary (partition) key.
you just need the table’s name and the partition key’s value to look for.
single attribute scan request:
protected ScanRequest scanSingleAttribute(final String attrValue, final String attrName,
final String filterExpression, final String tableName) {
Map<String, AttributeValue> valueMap = new HashMap<>();
valueMap.put(attrName, AttributeValue.builder().s(attrValue).build());
return ScanRequest.builder()
.tableName(tableName)
.expressionAttributeValues(valueMap)
.filterExpression(filterExpression)
.build();
}
this method builds a request that will return a list of items looking for a single attribute on the records.
you need the table’s name, the attribute you will be querying and a filtering expression for your given attribute.
Build and deploy
this note assumes you know your way around aws cli, aws sam, and other tools, so I won’t get on the details on how to build and deploy, but there is a recommendation worth mentioning.
Build
you could, if you have GraalVM locally installed, do a native compilation against your local and upload that to AWS. In my case, although without errors locally or reported by cloudformation while deploying, it failed to run on AWS Lambda once called with basic system library errors.
the problem lied in discrepancies between my local libraries used to compile the native code, and the ones on AWS lambda servers (told u there were servers behind the scenes…). The way to fix this is to not use your local installation for the compilation but instead use the docker image Quarkus relies on.
for that u only need to run the following.
mvn package -Pnative -Dquarkus.native.container-build=true
that last argument tells Quarkus to use a container for the native compilation. This is also handy for MacOS, BSD, Windows, etc users.
Deploy
to deploy having SAM installed on your machine, just run:
sam deploy -t target/sam.native.yaml -g
and follow the prompts
Taking all of this for a spin
when the code is deployed and the articles and users tables are populated with some records you get the following results
REST system configuration
- Lambda:
- memory: 128 MB
- provisioning / concurrency: no
- Dynamo relevant properties:
- read capacity: on demand
- write capacity: on demand
from the above you can see that all the stack is serverless and nothing is already provisioned to speed up coldStarts. This is on purpose as it is the most cost-effective solution, and the start-up time added by aws instantiating our resources will be handsomely rewarded by low billing.
if you don’t mind a little higher cost, you can have dynamo provisioned instead of on demand.
Performance on first hit.
disable caching on your browser, or use a tool such as postman, and hit the all articles endpoint; you will experience the system starting.
go ahead and hit it again… instant response correct?
let’s check the cloudwatch logs:
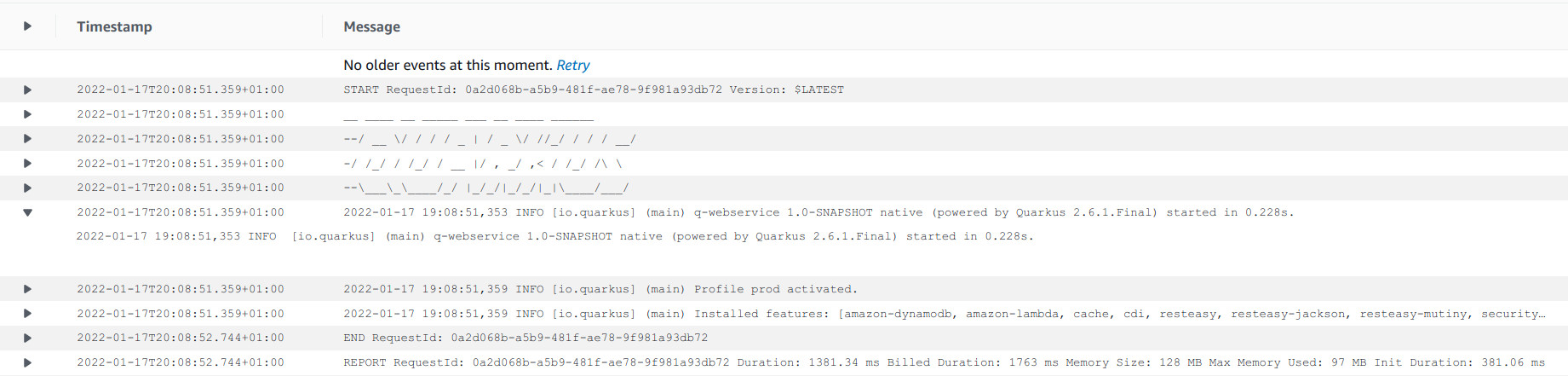
as u can see, Quarkus starts in 200ms. The whole round trip thou takes almost 1800ms, as stated above, lambdas and dynamos are all cold-starting which adds time to our java system itself. For a faster cold-start provision dynamo and retry!
another noteworthy detail… our system is using just 100 MB…
so, yes… java starting up in 200ms with a 100 MB memory footprint!
Performance on subsequent hits.
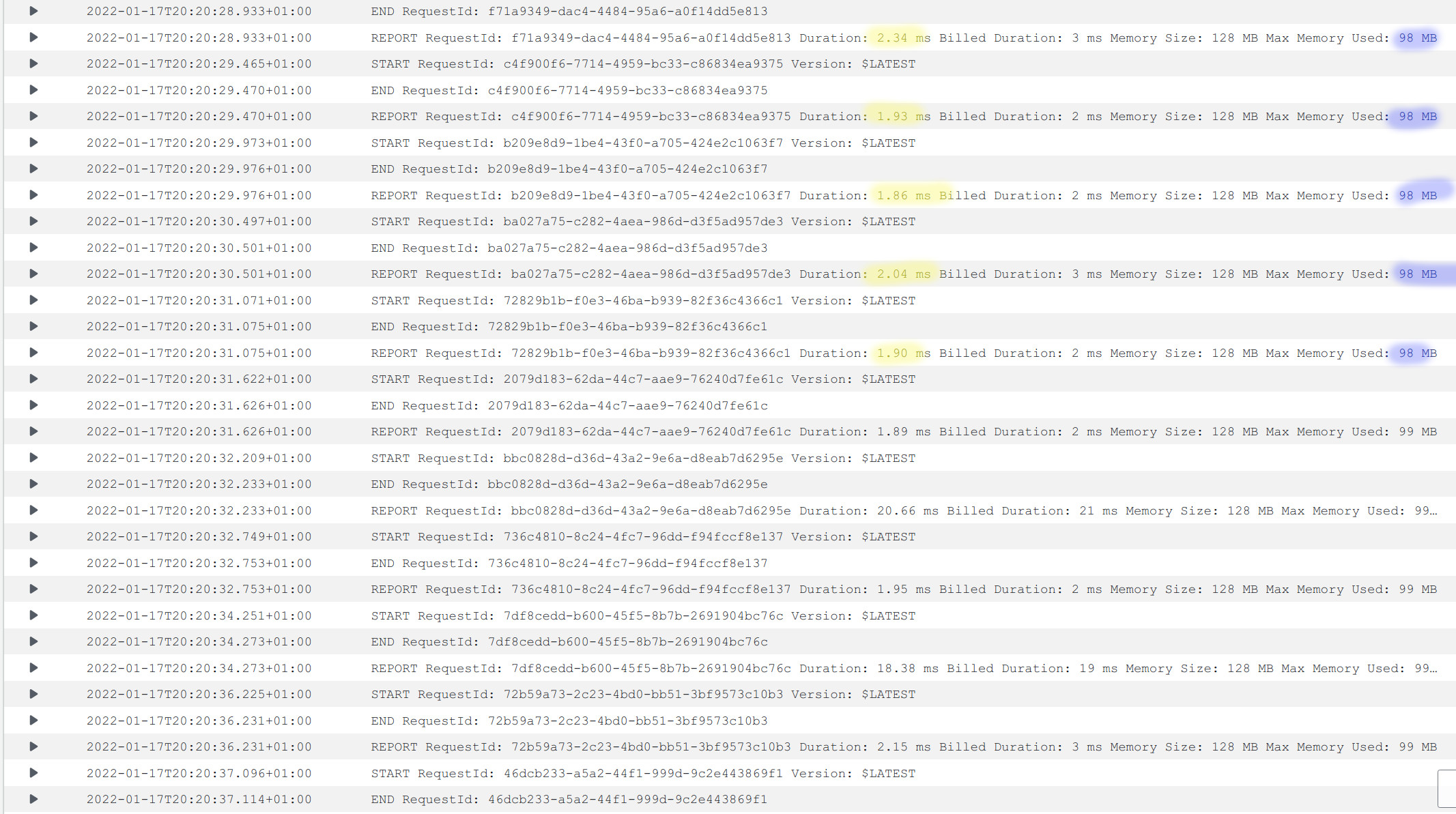
so, most of our responses are around 2ms… TWO, this is almost as fast as it could go.
regarding memory we are still around the 100 MB mark.
Why caching on a Lambda
why put caching on a system that has a short life span, right?! Remember that the objective is to be as cost-effective as possible exploring a java alternative.
let’s put the magnifying glass on the subsequent hits screenshot while remembering that to use caching it only took us a java @Annotation
we are returning from the lambda in 2ms! This gives us an incredible performance, and we are billed for 2 millis of compute time… I believe it is as low as it can be billed!
it does not end there… given that the responses are cache hits, we are saving ourselves many roundtrips from lambda to dynamo and back…
this actually means not only our lambda cost is as low as possible, but we eliminated several read requests and traffic on the dynamoDB side!!!
THAT is why caching on our short-lived lambdas makes sense!
Final notes
AWS Lambda caveats
not everything is roses and unicorns thou. With AWS serverless advantages come some restrictions you need to know about.
running time and payload size are limited and, as lambdas are provisioned on the fly, cold-start time of your app can be something to think about (a lot…) if you are chaining a few of these components…
the above touches closely the implementation language of choice, as some languages are very fast to start and others will take quite some time.
other custom environment on lambdas
there are other back-end languages that I discarded, that being potentially faster have higher hidden costs somewhere else, like c, c++, rust, goLang. The hidden costs could be: fewer devs in the market, steeper learning curves, fewer multipurpose business libraries, longer time to market, etc. Yes c is faster and boots faster, and sure maybe you love Go or zig as a business app language for some reason and decide it’s the right fit. (Life goes on Lukitas… ;-) )
tapping the expertise of your current staff
hoping your current JVM devs will be AS good coders outside their comfort language is just well-wishing. I (and we probably all) have, witnessed experienced pro devs / managers say that “javascript is plain easy, python is so obvious, piece of cake…”. Sure they are…
These findings, thou, will allow your java devs to exploit their knowledge to the max.
the general problem
this simple architecture and the conclusions drawn from this experiment don’t make AWS serverless a master key for every problem.
remember to think where this tool fits in your system, instead of forcing your system to fit this tool (or any other…)
a bigger problem
this system tackles very simple requirements, on a follow-up note we’re going to build a more complex architecture, to use the serverless stack as a fast, cost-effective, event driven system!
hope you enjoyed!
Johnny